GetOption was introduced to the NotesDatabase class in V6. It allows to determine, if specific options are set or not.
By design, it only accesses $dboptions1 from the database. Other options are stored in $dboptions2 – 4. Those option bits are not accessible using NotesDatabase.getOption(optionName%).
Here is code to access them.
Public Type DBOPTIONS
options (3) As Long
End Type
Public Const W32_LIB = {nnotes.dll}
Public Const TUX_LIB = {libnotes.so}
Declare Function W32_NSFDbGetOptionsExt Lib W32_LIB Alias {NSFDbGetOptionsExt}_
(ByVal hdb As Long, retDbOptions As DBOPTIONS) As Integer
Declare Function W32_NSFDbOpen Lib W32_LIB Alias {NSFDbOpen}_
(ByVal dbName As String, hDb As Long) As Integer
Declare Function W32_NSFDbClose Lib W32_LIB Alias {NSFDbClose}_
(ByVal hDb As Long) As Integer
Declare Function TUX_NSFDbGetOptionsExt Lib TUX_LIB Alias {NSFDbGetOptionsExt}_
(ByVal hdb As Long, retDbOptions As DBOPTIONS) As Integer
Declare Function TUX_NSFDbOpen Lib TUX_LIB Alias {NSFDbOpen}_
(ByVal dbName As String, hDb As Long) As Integer
Declare Function TUX_NSFDbClose Lib TUX_LIB Alias {NSFDbClose}_
(ByVal hDb As Long) As Integer
Public Function NSFDbGetOptionsExt (hDb As Long, retDbOptions As DBOPTIONS)
If isDefined("WINDOWS") Then
NSFDbGetOptionsExt = W32_NSFDbGetOptionsExt(hDb, retDbOptions)
Else
NSFDbGetOptionsExt = TUX_NSFDbGetOptionsExt(hDb, retDbOptions)
End If
End Function
Function NSFDbOpen( db As string, hDB As Long) As Integer
If isDefined("WINDOWS") Then
NSFDbOpen = W32_NSFDbOpen(db,hDb)
Else
NSFDbOpen = TUX_NSFDbOpen(db,hDb)
End If
End Function
Function NSFDBClose (hDb As Long)
If isDefined("WINDOWS") Then
NSFDbClose = W32_NSFDbClose(hDb)
Else
NSFDbClose = TUX_NSFDbClose(hDb)
End If
End Function
Sample:
Const DBOPT_IS_IMAP = &h01000000
Sub Initialize
Dim hDb As Long
Dim rc As Integer
Dim sDb As String
Dim retDbOptions As DBOPTIONS
sDb = "serv01/singultus!!mail/buser.nsf"
rc = NSFDbOpen(sDb, hDb)
If rc = 0 Then
rc = NSFDbGetOptionsExt (hDb, retDbOptions)
If retDbOptions.options(1) And DBOPT_IS_IMAP Then
MsgBox "IMAP enabled"
Else
MsgBox "IMAP not enabled"
End If
rc = NSFDbClose(hDb)
End If
End Sub
I have created an enhancement request for an optional method parameter to access the different optionsStores. If you think, that this might give you some benefit, pls upvote my idea https://domino.ideas.aha.io/ideas/DDXP-I-508
NotesDominoQuery by now does not support sorting of the results that come out of a query. John Curtis demoed at DNUG46 in Essen how you can get your results sorted. He showed the code only for a second, so I needed to rewrite it from scratch.
The method that he showed leverages from the new ‘maintainOrder’ property that has been added in V10 to the NotesViewEntryCollection class.
But let us first take a closer look at what is needed to make the code work.
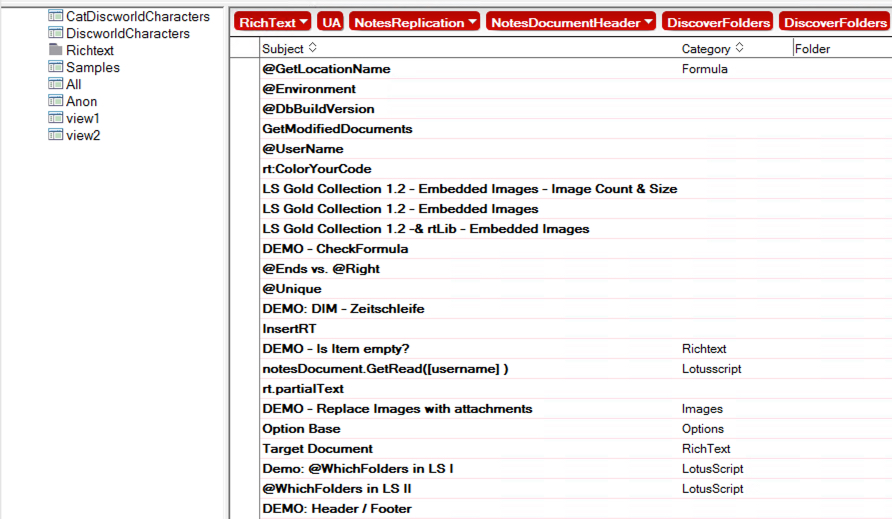
I have a small application where I store code snippets. I can categorize them and also test code locally or against a server.
In my sample, I want to get all documents from that application that have “DEMO” in the subject and output the subject in ascending order. Next I want to get the documents category in descending order.
Both columns, Subject and Category need to be prepared for sorting. They do not neccessarily have to be sorted initially.
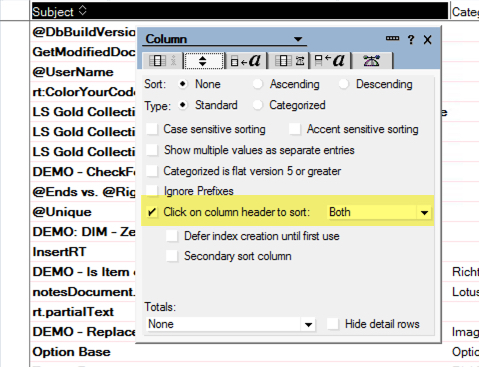
To set the sorting programmatically, I use the ‘Resortview’ method from the NotesView class. Be aware that the columnName must be the programmatic name of the column. Here is a sample how to use the ‘ResortView‘ method
Dim session As New NotesSession
Dim db As NotesDatabase
Dim view As NotesView
Dim vec As NotesViewEntryCollection
Set db = session.currentDataBase
Set view = db.getView("Samples")
' Sort By Subject
Call view.Resortview("Subject", true)
Set vec = view.Allentries
' Sort By Category
Call view.Resortview("category", false)
Set vec = view.Allentries
vec will now contain all view entries sorted ascending by Subject and after the second ResortView it will contail all view entries by Category in descending order.
You can use the following code to print the result to the console
Private Sub printIt(vec As NotesViewEntryCollection, itemName As String)
Dim ve As NotesViewEntry
Dim doc As NotesDocument
Dim item As NotesItem
Dim s As String
Set ve = vec.Getfirstentry()
While (Not ve Is Nothing)
s = "- no value -"
Set doc = ve.Document
Set item = doc.Getfirstitem(itemName)
If (Not item Is Nothing) Then
If (item.text <> "") Then
s = item.text
End if
End If
MsgBox s
Set ve = vec.Getnextentry(ve)
Wend
End Sub
Now lets add some code to query for all documents that have “DEMO” in the subject.
By now, DQL does not have the capability to build a query that uses CONTAINS. This will be added in a future version of Notes and Domino.
Dim session As New NotesSession
Dim db As NotesDatabase
Dim view As NotesView
Dim vec As NotesViewEntryCollection
Dim ve As NotesViewEntry
Dim col as NotesDocumentCollection
Dim doc As NotesDocument
Dim query As String
query = "Subject >= 'DEM' AND Subject < 'DEN'"
Dim dql As NotesDominoQuery
Set db = session.currentDataBase
Set view = db.getView("Samples")
Set dql = db.CreateDominoQuery()
Set col = dql.Execute(query)
Call view.Resortview("Subject", true)
Set vec = view.Allentries
Call vec.Intersect(col, true)
Call printIt(vec, "Subject")
Call view.Resortview("category", false)
Set vec = view.Allentries
Call vec.Intersect(col, true)
Call printIt(vec, "category")
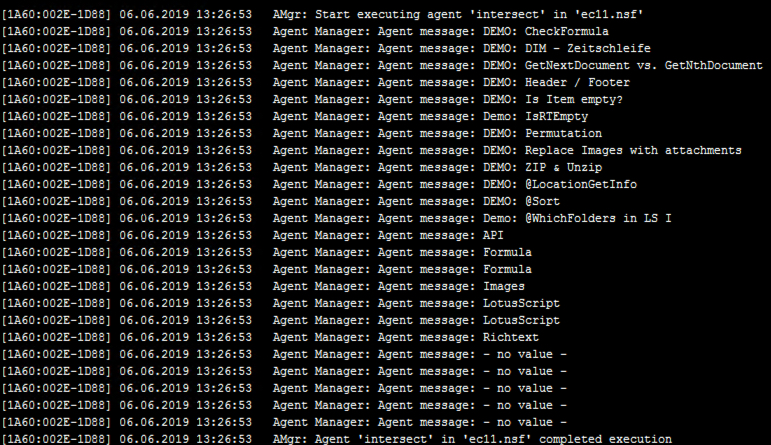
I put the code into an agent and ran that agent from the console. Here is the output.
If you are already using the NotesHTTPRequest and / or NotesJSONNavigator classes in your code and you are experiencing one of the following issues, here is an important technote for you.
SPR#DCONB8VMAV – NotesJSONNavigator is unable to parse JSON content > 64k
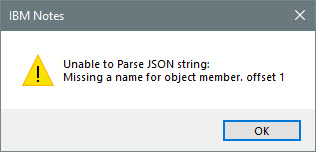
SPR#ASHEB95LFR – Unable to parse JSON string: Missing a name for object member, offset 1
SPR#DCONB8F6JV – bad character conversion happening in NotesHTTPRequest response
SPR#ASHEB95LFR – NotesJSONNavigator unable to navigate a string which contains new lines and carriage returns
SPR#DCONBB2KNR – NotesJSONNavigator experiencing severe issues when parsing packages with empty string values
SPR#JCORBB2KWU – Unable to Post > 64K String in NotesHTTPRequest
SPR#DCONBB44T4 – Creating a NotesJSONNavigator from nulled response causes crash
For high speed access to internal information about views and view columns, DQL processing uses design data extracted from view notes. Currently this information will be stored in a new database, named GQFdsgn.cat.
It is created using new updall flags. It does not replicate and is solely used as a fast-path tool to access design data at runtime.
Here is some LotusScript code to add / update the design of a named Notes application to the catalog. The NSFDesignHarvest call is currently undocumented. Use it at your own risk.
'DECLARATIONS
Public Const UPDATE_DESIGN_CATALOG = 0
Public Const ADD_TO_DESIGN_CATALOG = 1
Const NNOTES ="nnotes.dll"
Const LIBNOTES ="libnotes.so"
Declare Public Function WIN_NSFDbOpen Lib NNOTES Alias "NSFDbOpen" _
(ByVal dbName As String, hDb As Long) As Integer
Declare Public Function LIN_NSFDbOpen Lib LIBNOTES Alias "NSFDbOpen" _
(ByVal dbName As String, hDb As Long) As Integer
Declare Public Function WIN_NSFDbClose Lib NNOTES Alias "NSFDbClose" _
(ByVal hDb As Long) As Integer
Declare Public Function LIN_NSFDbClose Lib LIBNOTES Alias "NSFDbClose" _
(ByVal hDb As Long) As Integer
Declare Public Function WIN_NSFDesignHarvest Lib NNOTES Alias "NSFDesignHarvest" _
(ByVal hDb As Long, ByVal flag As Long) As Integer
Declare Public Function LIN_NSFDesignHarvest Lib LIBNOTES Alias "NSFDesignHarvest" _
(ByVal hDb As Long, ByVal flag As Long) As Integer
' API FUNCTIONS
Private Function NSFDbOpen( db As String, hDB As Long) As Integer
If isDefined("WINDOWS") Then
NSFDbOpen = WIN_NSFDbOpen(db,hDb)
ElseIf isDefined("LINUX") Then
NSFDbOpen = LIN_NSFDbOpen(db,hDb)
End If
End Function
Private Function NSFDbClose (hDb As Long)
If isDefined("WINDOWS") Then
NSFDbClose = WIN_NSFDbClose(hDb)
ElseIf isDefined("LINUX") Then
NSFDbClose = LIN_NSFDbClose(hDb)
End If
End Function
Private Function NSFDesignHarvest (hDb As Long, flag As long) As Integer
If isDefined("WINDOWS") Then
NSFDesignHarvest = WIN_NSFDesignHarvest(hDb, flag)
ElseIf isDefined("LINUX") Then
NSFDesignHarvest = LIN_NSFDesignHarvest(hDb, flag)
End If
End Function
Public Function catalogDesign(sDb As String, flag As Long) As Integer
Dim hDb As Long
Dim rc As Integer
If flag > 1 Then flag = 1
If flag < 0 Then flag = 0
rc = NSFDbOpen(sDb, hDb)
If rc = 0 Then
rc = NSFDesignHarvest(hDb, flag)
rc = NSFDbClose(hDb)
End If
catalogDesign = rc
End Function
To get some basic information about the installed Linux version you can use uname -a.
This will give you something like
Linux serv03.fritz.box 3.10.0-957.1.3.el7.x86_64 #1 SMP
Thu Nov 29 14:49:43 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
Well, we get the kernel version and the architecture.
rpm -qia ‘release‘ gives much more information
Name : nodesource-release
Version : el7
Release : 1
Architecture: noarch
Install Date: Thu 29 Nov 2018 09:01:53 AM CET
Group : System Environment/Base
Size : 3191
License : MIT
Signature : RSA/SHA256, Thu 04 Jan 2018 09:42:19 PM CET, Key ID 5ddbe8d434fa74dd
Source RPM : nodesource-release-el7-1.src.rpm
Build Date : Thu 04 Jan 2018 09:40:35 PM CET
Build Host : luthien
Relocations : (not relocatable)
URL : http://rpm.nodesource.com/pub_8.x/
Summary : N|Solid repository configuration
Description :
This package contains the NodeSource NodeJS repository
GPG key as well as configuration for yum.
Name : redhat-release-server
Version : 7.4
Release : 18.el7
Architecture: x86_64
Install Date: Tue 27 Nov 2018 01:50:07 PM CET
Group : System Environment/Base
Size : 43146
License : GPLv2
Signature : RSA/SHA256, Wed 28 Jun 2017 08:59:19 PM CEST, Key ID 199e2f91fd431d51
Source RPM : redhat-release-server-7.4-18.el7.src.rpm
Build Date : Wed 28 Jun 2017 08:36:32 PM CEST
Build Host : x86-037.build.eng.bos.redhat.com
Relocations : (not relocatable)
Packager : Red Hat, Inc. <http://bugzilla.redhat.com/bugzilla>
Vendor : Red Hat, Inc.
Summary : Red Hat Enterprise Linux Server release file
Description :
Red Hat Enterprise Linux Server release files
Name : epel-release
Version : 7
Release : 11
Architecture: noarch
Install Date: Wed 28 Nov 2018 07:54:48 AM CET
Group : System Environment/Base
Size : 24834
License : GPLv2
Signature : RSA/SHA256, Mon 02 Oct 2017 07:52:02 PM CEST, Key ID 6a2faea2352c64e5
Source RPM : epel-release-7-11.src.rpm
Build Date : Mon 02 Oct 2017 07:45:58 PM CEST
Build Host : buildvm-ppc64le-05.ppc.fedoraproject.org
Relocations : (not relocatable)
Packager : Fedora Project
Vendor : Fedora Project
URL : http://download.fedoraproject.org/pub/epel
Summary : Extra Packages for Enterprise Linux repository configuration
Description :
This package contains the Extra Packages for Enterprise Linux (EPEL) repository
GPG key as well as configuration for yum.
This is a pretty cool idea, I think. Although there already is a great tool available from Ytria ( agentEZ ), handling of agents should be a part of the core features of Notes / Domino.
Notes / Domino contains some of the requested features and for example, you can enable an agent via adminp. You can simply create a new admin request in the admin4.nsf; if you know, which values to set. Unfortunately, this is not documented and you have to do a lot of try and error before the admin request is processed. The advantage of using adminp would be documentation of who did what.
As a downside, you cannot disable an agent; there is no adminp request for that.
After reading Thomas’ idea, I decided to spend some hours on building a Domino server addin that would enable / disable or toggle the status of scheduled agents in an application. The application path, agent name and what to do should be passed as parameters to the addin.
Project “AMgr2” was born.
Over the years, I have created my own Notes cAPI CPP framework. This is still work in progress, as I add new methods and properties when I need them.
The framework is a great help when it comes to RAD in Notes / Domino using c/c++. I tried to name methods and properties as close as possible to what we have in LotusScript or Java to make the resulting source code readable and maintainable. Here is an example how I determine if an agent is of type “scheduled” within my framework
To build the cmdline parser, I use another framework that I wrote a couple of years ago. I used the Boost.Program_options in a couple of other projects before, but it is a lot of overhead for such a small project like AMgr2. CmdLine is much smaller. Despite of its simplicity, it is reliable and produces nice help screens.
I have not yet published CmdLine on Github. If you are interested in the source code, send me an email and I will send you the sources.
Putting it all together, we get a 64bit binary amgr2.exe Copy it to your Domino program directory and you are ready to go.
lo amgr2 -h and you should get
amgr2, V1.0.0.0, (c) 2019, Ulrich Krause
Usage: lo amgr2 [options] [flags]
Options:
-d --db database path
-a --agent agent name
Flags:
-h --help Prints this help
--enable Enable agent
--disable Disable agent
--toggle Toggle agent status
To enable a scheduled agent in an application type
lo amgr2 -d names.nsf -a test --enable
[219C:0002-1CE8] 17.02.2019 08:39:56 AMgr2: ... agent 'test' in database 'names.nsf' has been enabled
Use –disable to disable an agent or –toggle to change the status of an agent accordingly.
AMgr2 only works for scheduled agents. If an agent does not match this criteria, you’ll get the following message on the server console
lo amgr2 -d names.nsf -a test2 --toggle
[1F94:0002-15D8] 17.02.2019 08:47:53 AMgr2: ... agent 'test2' in database 'names.nsf' is not a scheduled agent
You also can build a simple Notes application that scans all applications on a server for scheduled agents. Next you can use NotesSession.SendConsoleCommand to enable / disable / toggle one or more agents.
Here is some sample code
Sub Click(Source As Button)
Dim session As New NotesSession
serverName$ = "serv01/singultus"
consoleCommand$ = Inputbox$("Type command:", _
"Send console command")
consoleReturn$ = session.SendConsoleCommand( _
serverName$, consoleCommand$)
Messagebox consoleReturn$,, consoleCommand$
End Sub
This might not be what Thomas asked for, but it is a good starting point. There is a lot room for improvements and enhancements. AMgr2 will sign the agent with the server id. This might not always be intended. It is not rocket science to implement code and add a couple of parameters to the cmdline parse to use a different id for signing. It is more work to make sure, this id is stored in a secure place and cnnot be accessed by any unauthorized person.
For now, this is it.
AMgr2 once again proves that you can do everything with Notes / Domino. The creators gave us tools that let us add functionallity that is not in the core code. OK, I admit that c/c++ is not the preferred programming language for most of the Notes / Domino developers.
UPDATE 05-FEB-2019: Issue is being tracked under SPR # VRARB94KAQ
When executing db.createDominoQuery(); in a Java agent on the server, I see the following error message on the Domino console:
te amgr run "ec11.nsf" 'dql.java'
[021963:000035-00007F2BE8DFD700] 02/03/2019 05:41:29 AM AMgr: Start executing agent 'dql.java' in 'ec11.nsf'
[021963:000037-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent printing: Version: Release 10.0.1 November 29, 2018
[021963:000037-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent printing: Db Title: singultus's Directory
[021963:000038-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: Exception in thread "AgentThread: JavaAgent"
[021963:000039-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: java.lang.UnsatisfiedLinkError: lotus/domino/local/Database.NcreateDQuery()J
[021963:000041-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: at lotus.domino.local.Database.createDominoQuery(Unknown Source)
[021963:000043-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: at JavaAgent.NotesMain(JavaAgent.java:19)
[021963:000045-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: at lotus.domino.AgentBase.runNotes(Unknown Source)
[021963:000047-00007F2BE816F700] 02/03/2019 05:41:29 AM Agent Manager: Agent error: at lotus.domino.NotesThread.run(Unknown Source)
[021963:000035-00007F2BE8DFD700] 02/03/2019 05:41:29 AM AMgr: Agent 'dql.java' in 'ec11.nsf' completed execution
According to John Curtis (HCL) “… We haven’t seen this to date.”.
I have tested on different OS.
serv02: Red Hat Enterprise Linux Server release 7.4 (Maipo) Linux serv02.fritz.box 3.10.0-693.el7.x86_64 #1 SMP Thu Jul 6 19:56:57 EDT 2017 x86_64 x86_64 x86_64 GNU/Linux IBM Domino (r) Server (64 Bit) (Release 10.0.1 for Linux/64) 02/03/2019 05:48:40 AM serv02 has been upgraded from V10.0
serv03: CentOS Linux release 7.6.1810 (Core) Linux serv03.fritz.box 3.10.0-957.1.3.el7.x86_64 #1 SMP Thu Nov 29 14:49:43 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux IBM Domino (r) Server (64 Bit) (Release 10.0.1 for Linux/64) 02/03/2019 05:49:15 AM (Community server) serv03 is "fresh" install and not upgraded from earlier Domino versions.
As it works on Domino 10.0.1 on WINDOWS, I investigated nlsxbe.dll and liblsxbe.so
nlsxbe.dll contains the function in question
Java_lotus_domino_local_Database_NcreateDQuery 0x0000000180017cd0 0x00017cd0 732 (0x2dc) nlsxbe.dll W:\Domino\nlsxbe.dll Exported Function
liblsxbe.so is missing the function. At least, it is not exported.
nm -D liblsxbe.so | grep createD
0000000000096a03 T Java_lotus_domino_local_Database_NcreateDocColl 0000000000095587 T Java_lotus_domino_local_Database_NcreateDocument 000000000012bf7d T Java_lotus_domino_local_DateRange_NrecreateDateRange 00000000000e33e1 T Java_lotus_domino_local_DateTime_NrecreateDateTime 0000000000110ad2 T Java_lotus_domino_local_DbDirectory_NcreateDatabase 00000000000d5d6d T Java_lotus_domino_local_Session_NcreateDateRange 00000000000da091 T Java_lotus_domino_local_Session_NcreateDateTime 00000000000d6bd1 T Java_lotus_domino_local_Session_NcreateDxlExporter 00000000000d6d71 T Java_lotus_domino_local_Session_NcreateDxlImporter 00000000000957a0 T Java_lotus_notes_Database_NcreateDocument 0000000000110d7e T Java_lotus_notes_DbDirectory_NcreateDatabase 00000000000d5f40 T Java_lotus_notes_Session_NcreateDateRange 00000000000da360 T Java_lotus_notes_Session_NcreateDateTime U _ZN11XmlDocument14createDocumentEv U _ZN11XmlDocument22createDocumentFragmentEv
The version and date seem to be OK.
ls -al liblsxbe.so -rwxr-xr-x. 1 root root 14510400 Nov 29 07:48 liblsxbe.so
Perhaps someone else can confirm this behaviour. I have already created case #TS001863705 with HCL.
SyntaxHighlighter Evolved: LotusScript Brush is a small WordPress plugin that adds support for the LotusScript language to the great SyntaxHighlighter Evolved plugin by Alex Mills.
I have submitted a request to add the plugin to the official WordPress plugin directory. The review process will take some time.
In the meantime, you can start using SyntaxHighlighter Evolved: LotusScript Brush right now.
Download the plugin from here , unpack it and upload to your /wp-content/plugins directory.
Update 04-FEB-2019: The plugin is now available in the WordPress plugin directory.
Next activate the plugin
SyntaxHighlighter Evolved: LotusScript Brush will now be available as a new language in the Block Editor (“Code Languages”)
SyntaxHighlighter Evolved: LotusScript Brush highlights classes, method and properties, keywords, strings, comments and directives.
Think about a big database with lots of documents in it and you want to find only one particular document. You can do that with FTSearch, or you can use a db.search with some formula.
As of V10.0.x, you also have DQL and the new NotesDominoQuery class. The class is available in Lotsscript and Java. I want to demonstrate in this sample, how you can find the needle in the haystack with DQL in Lotusscript.
My database has about 12.500.000 Documents. It is one of our customers database at midpoints. The amount of documents was created by accident. Some call it a bug. Anyway, the database is a good playground.
The code is typical for a LS developer. It initiates objects and stuff, assigns variables like our dqlTerm (line 6 see the similarity to the @formula, you would probably use with db.search? ), does a check, if the target database is open (line 9 ) and also has some basic error handling (17, 20-21). We will come to that later.
I am running the sample on the client. As of today , you cannot run a query client / server. I will show in another post, how you can run the query on the server and work with the results on the client. But that is another story.
public Sub foo()
Dim session As New NotesSession
Dim db As NotesDatabase
Dim col As NotesDocumentCollection
Dim dqlTerm As String
dqlTerm = "form = 'frm.rules.device.rule' And rule_unid = '99A242AAB69B5BB9C1257FFC005DE6C4'"
Set db = session.Getdatabase("","trul-big.nsf", False)
If db.Isopen Then
Dim dql As NOTESDOMINOQUERY
Set dql = db.CreateDominoQuery()
Dim parse_result As String
parse_result = dql.parse(dqlTerm)
If LCase(parse_result) = "success" Then
Set col = dql.Execute(dqlTerm)
MsgBox dql.Explain(dqlTerm)
Else
MsgBox parse_result
End If
End If
End Sub
Before you run the code and try to search such a huge amount of data, you need to set some notes.ini variables.
By now, there is no other way to increase the number of documents. There are setters in the NotesDominoQuery class, but those setters are broken. This is a known issue and HCL is working on a solution.
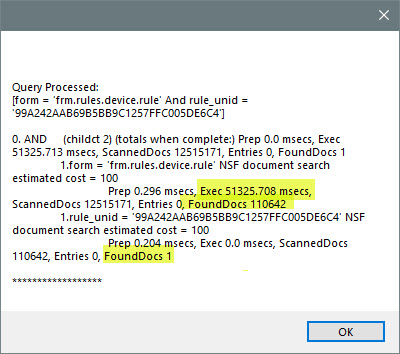
When we now run the code, we will get the following result
It took 51.3 secs to find 110642 documents that use the form “frm.rules.device.rule” and zero to none secs to find 1 document in that resultset.
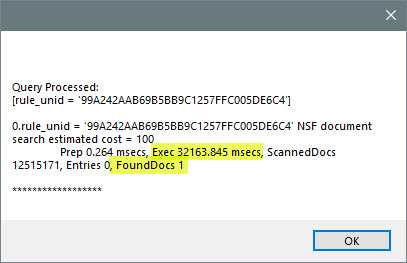
Would it be faster or slower, if we modify our query to use only the rule_unid field and search over the entire set of documents?
32.2 secs to find the needle in the haystack. Use this kind of single field search, if you are sure that the field “rule_unid” is only used on one form.
But even in the case that the field is used on another form; to filter the resulting NotesDocument collection afterwards is much faster than the AND dqlTerm from the original code.
Maybe, you already have a view in your application where the rule_unid is in a sorted column.
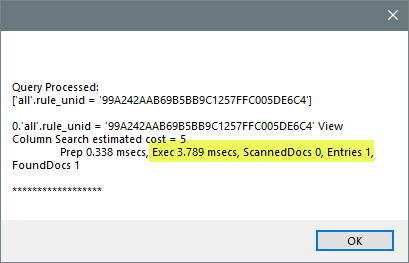
Then we can use a modified dqlTerm to find the document in that view.
THAT is pretty cool, isn’t it? 5.6 msecs to find the needle in the haystack.
Can it be even faster? I think no, but let us take another look at the code that does the query.
Dim parse_result As String
parse_result = dql.parse(dqlTerm)
If LCase(parse_result) = "success" Then
Set col = dql.Execute(dqlTerm)
MsgBox dql.Explain(dqlTerm)
Else
MsgBox parse_result
End If
We can safely remove all of our “Error handling”, that means lines 14-17 and 20-22. Why? Because dql.Excecute(dqlTerm) does the parse before executing the query.
So we end up with the following code
public Sub foo()
Dim session As New NotesSession
Dim db As NotesDatabase
Dim col As NotesDocumentCollection
Dim dqlTerm As String
dqlTerm = "'all'.rule_unid = '99A242AAB69B5BB9C1257FFC005DE6C4'"
Set db = session.Getdatabase("","trul-big.nsf", False)
If db.Isopen Then
Dim dql As NOTESDOMINOQUERY
Set dql = db.CreateDominoQuery()
Set col = dql.Execute(dqlTerm)
MsgBox dql.Explain(dqlTerm)
End If
End Sub
When we run the code, we get
Keep in mind that the numbers vary a litte bit from run to run.
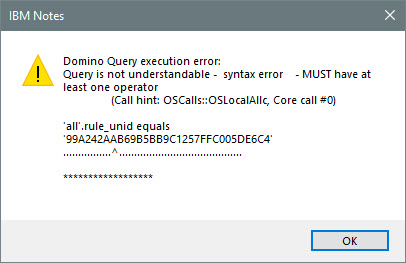
If we now modify our dqlTerm and add an error, we are shown a nice dialog box explaining the error in detail.
That’s all for today, I hope you find this information useful.
I received the following mail from IBM announcing the End of Marketing for all Watson Workspace offerings and ending the Watson Workspace service on 2/28/19.
Watson Workspace Announcement
Tomorrow, Tuesday 15 Jan 2019, IBM will formally announce the End of Marketing for all Watson Workspace offerings and we anticipate ending the Watson Workspace service on 2/28/19. This includes Watson Workspace Essentials, Plus, and the free offering. It is our intent to ensure that you have a clear understanding of your options regarding the closure of Watson Workspace. While there is no question that Watson Workspace is innovative and agile, it hasn’t resonated with clients or obtained the traction in the marketplace necessary for IBM to continue forward with the service. Despite our best efforts and enthusiasm for these offerings, our decision to withdraw them aligns to IBM’s investment strategy, focused on delivering solutions that deliver measurable value to our customers and business partners. IBM has stopped accepting new orders for Watson Workspace products, and we will not be adding any new features to the offerings. We have been working with our licensed customers and business partners to provide options for handling subscriptions and contracts once the end of service announcement is published to provide a smooth transition. Starting tomorrow there will be a banner placed into the UI of Watson Workspace informing users of the timeline for moving off the service. Mobile customers may find details in the release notes of the mobile app. We will also provide access to a tool that will allow you to download and save your conversations and content from Watson Workspace. Please plan accordingly to capture any content you’d like to retain as we work to sunset the service. This option will only be available for a limited time. Thank you for your support of Watson Workspace and IBM Collaboration Solutions. Please find additional details and answers to commonly asked questions in the FAQ that will be posted in the Watson Workspace banner tomorrow.
%REM
Library 10010.http
Created Jan 8, 2019 by Ulrich Krause/singultus
%END REM
Option Public
Option Declare
Const BASE_URL_PORT = "http://192.168.178.35:3001/api/"
Const CLASS_CUSTOMER ="customers"
Const CUSTOMER_5 = |{
"firstname" : "Ulrich",
"lastname" : "Krause",
"age" : 59,
"id" : 5
}|
Const CUSTOMER_5_UPDATE = |{
"firstname" : "Heinz Ulrich",
"lastname" : "Krause",
"age" : 59,
"id" : 5
}|
%REM
Class HttpRequestWrapper
%END REM
Public Class HttpRequestWrapper
Private m_session As NotesSession
Private m_url As String
Private m_class As String
Private m_json As String
Private m_httpRequest As NOTESHTTPREQUEST
%REM
Sub New
%END REM
Public Sub New()
Set m_session = New NotesSession
Set m_httpRequest = me.m_session.CreateHttpRequest()
m_httpRequest.Preferstrings = True
m_url = BASE_URL_PORT
m_class = CLASS_CUSTOMER
End Sub
%REM
Function getApiVersion
%END REM
Public sub getApiVersion()
m_json = m_httpRequest.Get(BASE_URL_PORT)
MsgBox m_json
End Sub
%REM
Sub getAllObj
%END REM
Public Sub getAllObj()
m_json = m_httpRequest.Get(_
BASE_URL_PORT + CLASS_CUSTOMER)
MsgBox m_json
End Sub
%REM
Sub getObjById
%END REM
Public Sub getObjById(id As String)
m_json = m_httpRequest.Get(_
BASE_URL_PORT + CLASS_CUSTOMER + "/" + id)
MsgBox m_json
End Sub
%REM
Sub createObj
%END REM
Public Sub createObj()
m_json = m_httpRequest.Post(_
BASE_URL_PORT + CLASS_CUSTOMER,_
removeCRLF(CUSTOMER_5))
MsgBox m_json
End Sub
%REM
Sub updateObj
%END REM
Public Sub updateObj(id As String)
m_json = m_httpRequest.Put(_
BASE_URL_PORT + CLASS_CUSTOMER + "/" + id,_
removeCRLF(CUSTOMER_5_UPDATE))
MsgBox m_json
End Sub
%REM
Sub deleteObj
%END REM
Public Sub deleteObj(id As String)
m_json = m_httpRequest.DeleteResource(_
BASE_URL_PORT + CLASS_CUSTOMER + "/" + id)
MsgBox m_json
End Sub
End Class
Public Function removeCRLF(json As String) As String
removeCRLF = Replace(Replace(json, Chr(13), ""),Chr(10),"")
End Function
Sample usage:
Use "10010.http"
Sub Click(Source As Button)
Dim httpRequestWrapper As New HttpRequestWrapper()
Call httpRequestWrapper.getApiVersion()
Call httpRequestWrapper.createObj()
Call httpRequestWrapper.deleteObj("3")
Call httpRequestWrapper.getAllObj()
Call httpRequestWrapper.updateObj("5")
Call httpRequestWrapper.getObjById("5")
End Sub
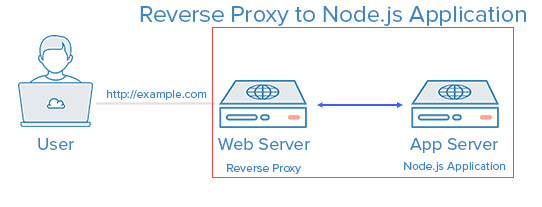
I have setup a new Node.js / Express development environment on a CentOS 7 VM. I ‘ll describe the details in another post later.
To test my setp, I created a new Express application “helloworld”. The application listens on port 3000 and I was able to connect to the application using a browser.
Next, I configured NGINX as reverse proxy to use port 80 to access the helloworld application.
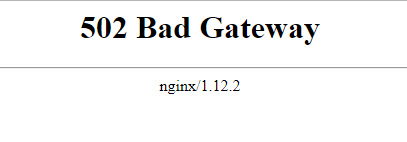
[root@nodejs ~]# getsebool -a | grep httpd httpd_anon_write --> off httpd_builtin_scripting --> on httpd_can_check_spam --> off httpd_can_connect_ftp --> off httpd_can_connect_ldap --> off httpd_can_connect_mythtv --> off httpd_can_connect_zabbix --> off httpd_can_network_connect --> off httpd_can_network_connect_cobbler --> off httpd_can_network_connect_db --> off httpd_can_network_memcache --> off httpd_can_network_relay --> off httpd_can_sendmail --> off
So, httpd_can_network_connect was set to “Off”. This blocks the connection from the reverse proxy to the node.js application. As a result, you get the 502 Bad gateway error.
To enable the setting, execute the following command from the shell.
[root@nodejs ~]# setsebool -P httpd_can_network_connect on
(replace the highlighted version with the version you want to upgrade to )
This time, the update failed.
[InstallationError] Failed to setup upgrade using esx-update VIB: (None, "Failed to mount tardisk /tmp/esx-update-2123405/esxupdt-2123405 in ramdisk esx-update-2123405: [Errno 1] Operation not permitted: '/tardisks.noauto/esxupdt-2123405'") vibs = ['VMware_bootbank_esx-update_6.7.0-1.31.10764712'] Please refer to the log file for more details. [root@esxi:~]
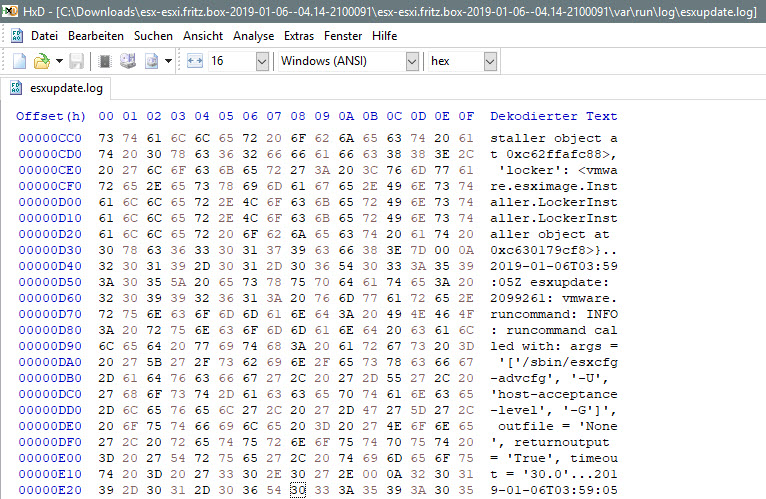
Digging into the logs, I found the following clues
vmkernel.log: cpu1:2099635)ALERT: VisorFSTar: 1655: Unauthorized attempt to mount a tardisk cpu1:2099635)VisorFSTar: 2062: Access denied by vmkernel access control policy prevented creating tardisk
esxupdate.log: esxupdate: 2099635: root: ERROR: File "/build/mts/release/bora-10302608/bora/build/esx/release/vmvisor/sys-boot/lib64/python3.5/shutil.py", line 544, in move esxupdate: 2099635: root: ERROR: PermissionError: [Errno 1] Operation not permitted: '/tmp/esx-update-2123405 /esxupdt-2123405' -> '/tardisks.noauto/esxupdt-2123405 '
By the way, the esxupdate.log is in HEX format for some reason.
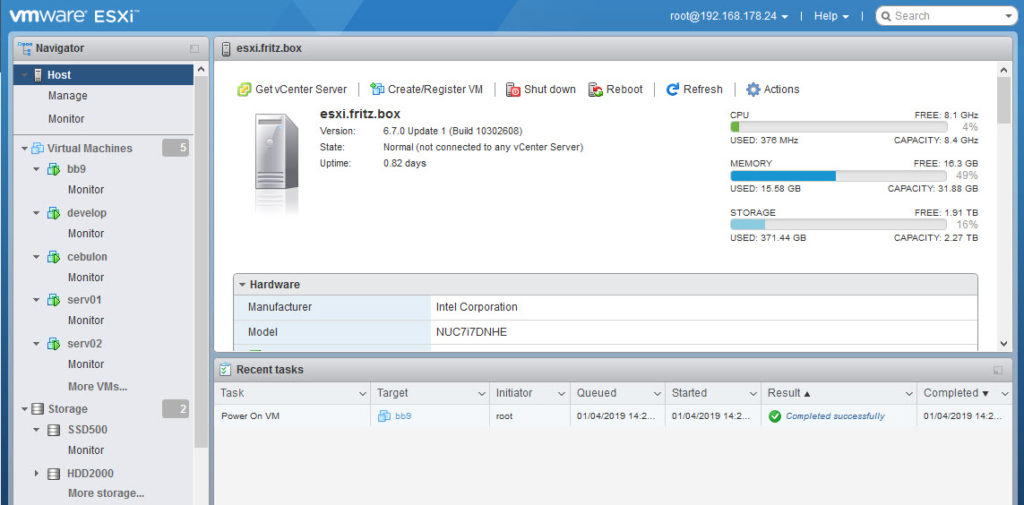
I recently decided that it is time to setup a new homelab. The old server is about 10 yrs old. The hardware does not allow any upgrade in CPU and Ram. VMWare ESXi was version 6.5, but I could not upgrade to version 6.7 because the network card was not in the list of supported NICs and so the upgrade failed. Last, but not least, the power consumption was at 200W.
It took less than 30 minutes to assemble the NUC and install VMWare ESXi 6.7. ( + 15 minutes to drive to the local hardware store to grab an USB keyboard once I realized that I would need one for the setup )
Today, I migrated the existing VMs from the old host to the new one.
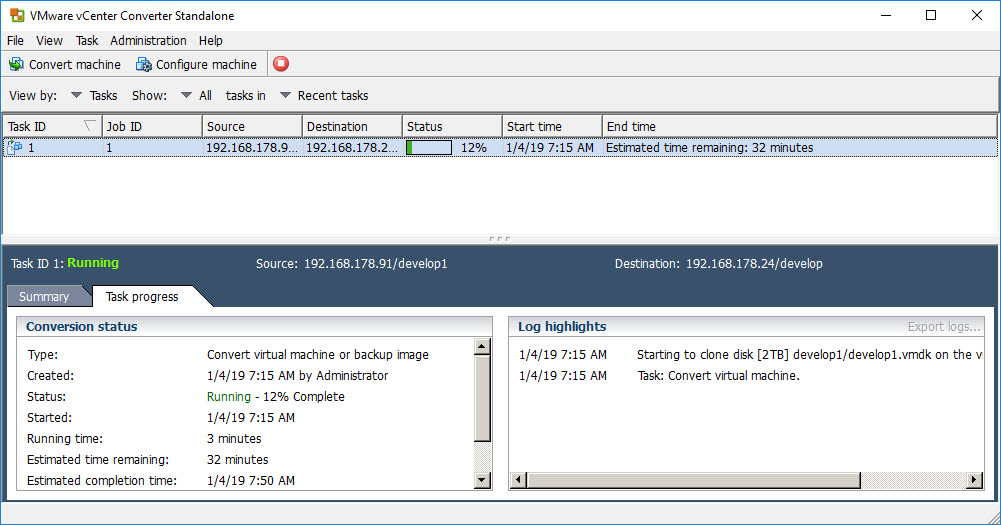
ESXi does not include VMotion. VMotion costs a lot of money. I had read some articles which claimed to be best practice. But to be honest, using Veeam or SCP are not, what I consider “best” practice. I tried SCP, but it was so slooooow. Even a 50GB VM was estimated 11 hours to copy. And I have 30 VMs from just a couple of MB to 100GB.
You simply choose the “source” ESXi instance and select the VM to copy. Next you select the “target” ESXi. You can also choose, if the copy will be automatically updated to the target VM version.
It took only 30 minutes to copy a 50GB VM. Another 100GB VM was copied in 20 minutes.
The whole migration was done in only 5 hours. Not bad, isn’t it.
Const white = |{"color": "white", "category": "value","code": {"rgba": [0,0,0,1],"hex": "#FFF"}}|
Public Sub testJsonNavGetElementByPointer()
Dim session As New NotesSession
Dim jsnav As NotesJSONNavigator
Dim el As NOTESJSONELEMENT
Set jsnav = session.CreateJSONNavigator(removeCRLF(white))
'// returns "value"
Set el = jsnav.Getelementbypointer("/category")
MsgBox "category: " + el.Value
'// returns "#FFF"
Set el = jsnav.Getelementbypointer("/code/hex")
MsgBox "hex: " + el.Value
'// returns the 4th element in the rgba array "1"
Set el = jsnav.Getelementbypointer("/code/rgba/3")
MsgBox "code/rgba/3: " + el.Value
End Sub
I stumbled upon an issue with NotesJsonNavigator getNthElement(index) method.
It looks like there is no boundry check, which leads to some inconsitent behaviour and unpredictable results.
Here is the code that I used in my test.
%REM
Sub testJsonNavGetNthElement
%END REM
Public Sub testJsonNavGetNthElement
Dim s As New NotesSession
Dim jsnav As NotesJSONNavigator
Dim el As NotesJSONElement
Set jsnav = s.CreateJSONNavigator(|{ "element1" : "value 1", "element2" : "value 2", "element3 ": "value 3" }|)
Set el = jsnav.GetNthElement(0)
Stop
Set el = jsnav.GetNthElement(1)
Stop
Set el = jsnav.GetNthElement(2)
Stop
Set el = jsnav.GetNthElement(3)
Stop
Set el = jsnav.GetNthElement(1000)
Stop
End Sub
The issue occurs with index < 1 and > upper bound of the array.
Index 0 AND index 1 both return the same value; “value 1“. Index 1000 returns NULL or nothing.
This is not the expected behaviour. At least I would expect some “out of bounds” error. Also, it is not clear for me what the base for the index is. Do we start counting at 0 or do we start with 1 ?
According to the documentation, the index is 1-based.
The documentation also contains some basic samples.
In this article, I will demonstrate how to use the classes beyond the basic examples. I’ll also show, how you can use the newNotesHttpRequest class to connect to a server and read and parse view data as JSON.
The first thing you need to know is that the NotesJsonNavigator class does not like CRLF. When you try to create a new NotesJsonNavigator from the following JSON data
You can remove all CRLF from the data using this helper function.
Public Function removeCRLF(json As String) As String
removeCRLF = Replace(Replace(json, Chr(13), ""),Chr(10),"")
End Function
Let us create the NotesJsonNavigator from NotesSession first.
Dim session As New NotesSession
Dim jsnav As NotesJSONNavigator
Dim json As String
json = removeCRLF(colors)
Set jsnav = session.CreateJSONNavigator(json)
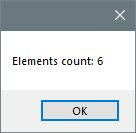
Now we can count how many different colors we would find in our JSON object
Dim el As NOTESJSONELEMENT
Dim arr As NOTESJSONARRAY
Set el = jsnav.GetFirstElement()
Set arr = el.value
MsgBox "Elements count: " + CStr(arr.size)
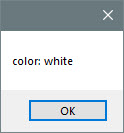
And finally, we want to get the value for the second color in the JSON object.
Although there is a GetNthElement (index) method, this method seems to be buggy or not yet fully implemented. GetNthElement(index) will always return the first element from the JSON object.
So we will use GetFirstElement and GetNextElement to navigate thru the object.
'Set el = arr.Getnthelement(2)
Set el = arr.GetFirstElement()
Set el = arr.GetNextElement()
Dim obj As NOTESJSONOBJECT
Set obj = el.Value
Set el = obj.Getelementbyname("color")
MsgBox "color: " + CStr(el.Value)
The next sample creates a NotesHttpRequest and gets JSON from a view in a Notes application. Then we retrieve the UNID and NoteId from the data returned using the new NotesJson… classes.
%REM
Library 10010.http
Created Jan 1, 2019 by Ulrich Krause/singultus
Description: Comments for Library
%END REM
Option Public
Option Declare
Public Sub httpGet
Dim Session As New NotesSession
Dim ret As String
Dim URL As String
Dim user As String
Dim password As String
Dim httpReq As NotesHTTPRequest
Set httpReq = session.CreateHttpRequest()
httpReq.Preferstrings = True
user = "firstname.lastname@tld.de"
password = "pAssw0rd"
URL = "https://yourserver/names.nsf/($certifiers)?readviewentries&outputformat=JSON"
Call httpReq.Setheaderfield("Authorization", "Basic " + EncodeBase64 (user + ":" + password))
Dim json As string
json = httpReq.Get(URL)
Dim jsnav As NotesJSONNavigator
Set jsnav = session.CreateJSONNavigator(removeCRLF(json))
Dim el As NOTESJSONELEMENT
Dim arr As NOTESJSONARRAY
Dim obj As NOTESJSONOBJECT
Set el = jsnav.GetElementByName("viewentry")
Set arr = el.value
Set el = arr.GetFirstElement()
Set el = arr.GetNextElement()
Set obj = el.Value
Set el = obj.Getelementbyname("@unid")
MsgBox "unid: " + CStr(el.Value)
Set el = obj.Getelementbyname("@noteid")
MsgBox "noteid: " + CStr(el.Value)
End Sub
Private Function removeCRLF(json As String) As String
removeCRLF = Replace(Replace(json, Chr(13), ""),Chr(10),"")
End Function
Private Function EncodeBase64 (StrIn As String) As String
Dim session As New NotesSession
Dim stream As NotesStream
Dim db As NotesDatabase
Dim doc As NotesDocument
Dim body As NotesMIMEEntity
Set stream = session.CreateStream
Call stream.WriteText (StrIn)
Set db = session.CurrentDatabase
Set doc = db.CreateDocument
Set body = doc.CreateMIMEEntity
Call body.SetContentFromText (stream, "", ENC_NONE)
Call body.EncodeContent (ENC_BASE64)
EncodeBase64 = body.ContentAsText
Call stream.Close
Set doc = Nothing
End Function